
If your team is asking what is llms.txt, start with the practical definition: LLMs.txt is a Markdown file, usually placed at /llms.txt, that gives language models and AI agents a curated map of the most useful pages on a website. For SEO teams, the important part is not the file name. The important part is the operating decision: which pages should an AI system read first, and what context should it see before it follows those links?
Use llms.txt as an AI-readable navigation layer, not as a guaranteed ranking signal. It can help documentation, product, and content-heavy sites explain their structure more cleanly to agents, but it does not replace crawl access, sitemap hygiene, canonical URLs, or useful content.
Start With The Real Job
The original llms.txt proposal describes a root Markdown file that helps LLMs use a website at inference time. The proposed format is intentionally simple: an H1 naming the site, a short summary, optional context, and H2 sections with Markdown lists of important URLs.
That makes llms.txt closer to a curated reading list than a search directive.
| Existing asset | Main job | What llms.txt adds |
|---|---|---|
robots.txt | Communicates crawl access rules | Context about what allowed content means |
| XML sitemap | Lists indexable URLs for discovery | A shorter, curated map of the most useful AI-readable pages |
| Schema markup | Describes entities and page facts | A plain-text entry point that points agents toward the right source pages |
| Navigation and internal links | Helps humans and crawlers move through the site | A compressed outline for tools with limited context windows |
The proposal also says llms.txt should coexist with current web standards. That is the right framing for SEO: add it only after the basic crawl and content layers are already clean.
Do Not Treat It Like A Ranking Switch
The safest SEO stance is conservative. The proposal does not define a single required processing behavior for every AI system, and public implementations vary by use case. That means llms.txt should not be sold internally as a direct path to AI Overview inclusion, chatbot citations, rankings, or traffic recovery.
The better question is whether your site has content that would benefit from a concise, AI-readable map.
| If the team believes | Replace it with this working assumption |
|---|---|
| "Adding llms.txt will make AI systems cite us." | "Adding llms.txt may make our important pages easier for agents to find and interpret." |
| "It is the robots.txt for AI." | "It complements robots.txt, but robots.txt still governs access rules." |
| "We should list every URL." | "We should list the canonical pages that explain the product, docs, policies, and best evidence." |
| "This is only a developer-docs thing." | "It is strongest for docs, but can also help structured resource libraries and clear product education." |
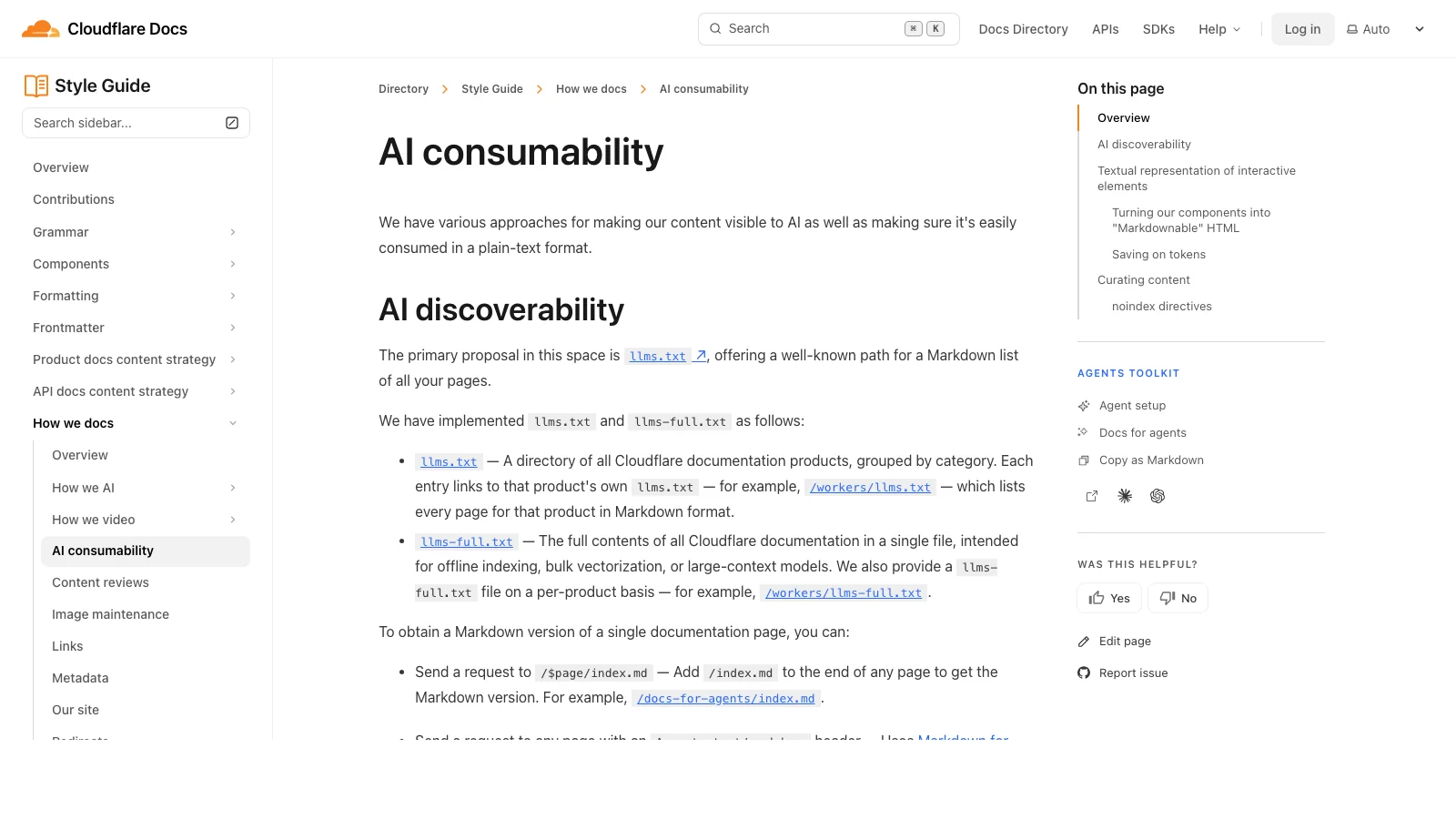
Cloudflare's AI consumability documentation is a useful public example because it frames llms.txt alongside Markdown access, content curation, and token efficiency. The file is part of a larger agent-readable content system, not a standalone SEO trick.
Decide If Your Site Actually Needs One
You do not need llms.txt for every five-page marketing site. You should consider it when the site has enough public knowledge that an agent needs a map.
Use this decision table:
| Site situation | llms.txt priority | Better first action |
|---|---|---|
| Developer docs, API docs, or technical references | High | Create a curated root file and product-specific child files |
| SaaS product with many use cases, docs, and comparison pages | Medium to high | Map product, docs, pricing, security, and support pages |
| Content library with many evergreen SEO resources | Medium | Point to hubs, canonical explainers, and update-sensitive references |
| Small brochure site | Low | Improve entity clarity, schema, and page copy first |
| Ecommerce store with thousands of products | Low to medium | Prioritize crawl rules, product schema, category pages, and canonical management |
| Site with thin, duplicate, or blocked pages | Low | Fix content quality and technical eligibility before adding a map |
Searvora already exposes a blog-level /blog/llms.txt route for recent articles. A sitewide llms.txt strategy would be broader: product pages, core use cases, docs or help pages, policy pages, and the strongest evergreen articles should be deliberately selected instead of dumped into one file.
Build It From Canonical URLs And Markdown-Friendly Pages
The file should be boring to maintain. Start from canonical URLs and only include pages that you would be comfortable handing to a customer, a search quality reviewer, or an AI agent as source material.
Cloudflare's public root llms.txt shows a practical pattern: group products by category, link to product-scoped llms.txt files, and add short descriptions so the agent understands what each link is for.

Use this simple structure for an SEO-friendly first version:
| Section | Include | Avoid |
|---|---|---|
| H1 | Site or product name | Keyword stuffing |
| Summary | What the site does, who it serves, and what content is authoritative | A vague brand slogan |
| Product or service pages | Canonical product pages with stable descriptions | Campaign URLs and temporary pages |
| Documentation or help | Markdown-friendly docs, API references, support pages | Thin directory pages with no explanation |
| Research or evergreen articles | Original explainers, benchmarks, guides, and decision frameworks | Every blog post by date |
| Optional | Secondary reading that can be skipped when context is short | Business-critical pages that agents should always see |
For large sites, do not force thousands of URLs into one huge file. A root llms.txt can point to smaller files by directory, product, or content type. That keeps the map readable and reduces the chance that an agent spends its context window on low-value links.
Audit The File Like A Search Asset
An llms.txt file can drift just like a sitemap, navigation menu, or content hub. Treat it as a maintained asset.
Use this QA checklist before publishing:
- The file is reachable at
/llms.txtor a clearly documented subpath. - The H1 matches the entity or product name used on the homepage and schema.
- The summary says what the site is, who it helps, and what the listed pages cover.
- Every URL resolves to a clean canonical page, not a redirect, error, noindex page, or duplicate.
- The listed pages are readable without private login, cookie-gated content, or broken rendering.
- The file points to Markdown-friendly versions when they exist.
- The list excludes stale, thin, campaign-only, and low-context pages.
- The file has an owner and review cadence.
- The sitemap, robots rules, canonical tags, and internal links do not contradict it.
This is where normal technical SEO still matters. If your sitemap lists one URL, canonical tags point to another, and llms.txt links to a third, you have created more ambiguity. Pair the file with the technical SEO workflow and the GEO SEO foundations workflow so AI-readable content is still crawlable, indexable, and source-worthy.
Where Searvora Fits
Searvora AI SEO Dashboard fits the monitoring layer around llms.txt work. The product page positions the dashboard around page-type cohorts, locale drill-downs, anomaly detection, opportunity queues, and executive-ready summaries. That is the right model for llms.txt because the file should be reviewed alongside real visibility and technical evidence.
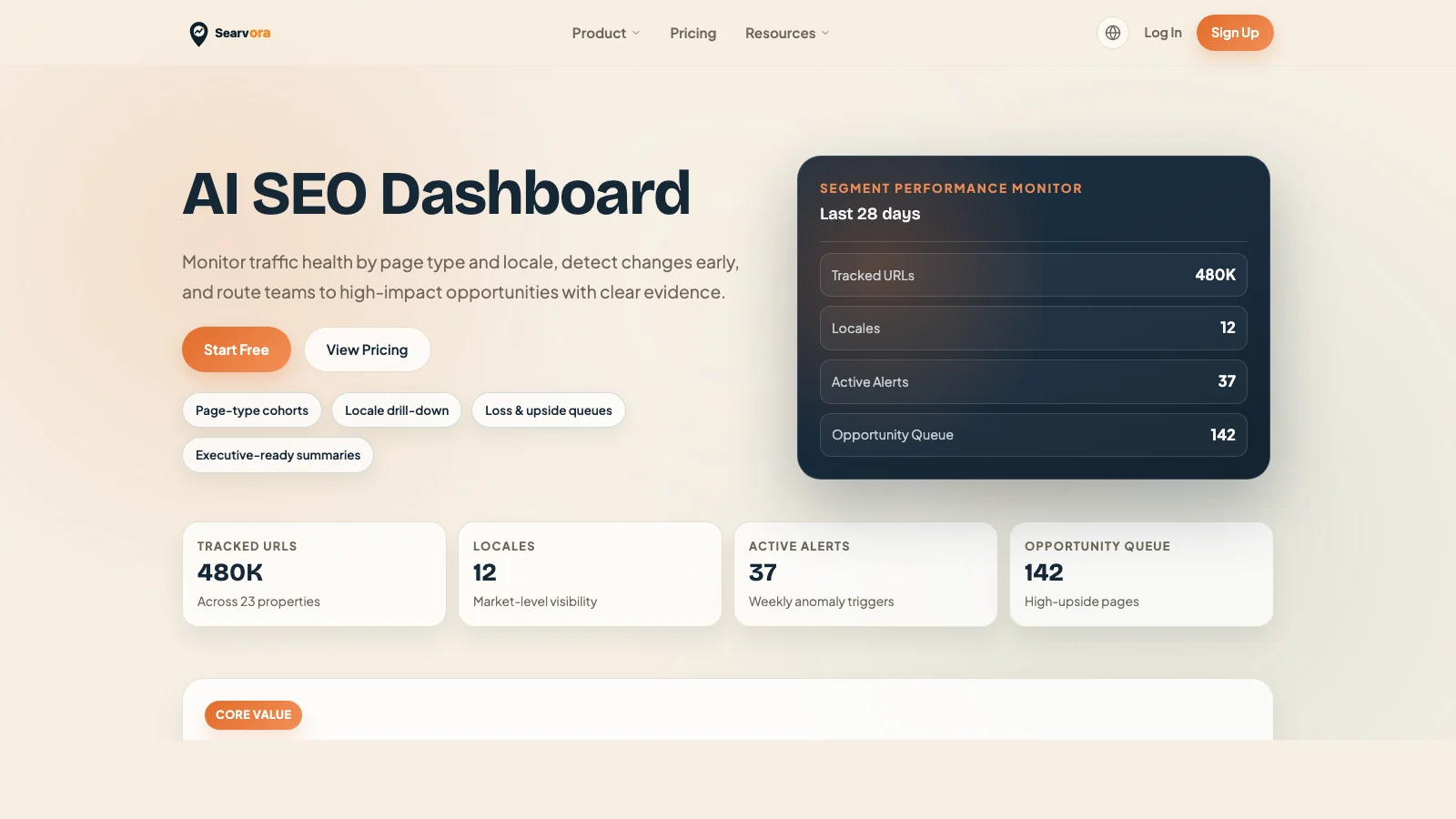
Use the dashboard to track whether the pages named in your llms.txt file are the same pages that deserve AI-search attention:
| Dashboard question | Why it matters for llms.txt |
|---|---|
| Which page types are gaining or losing visibility? | The file should point to pages with durable source value |
| Which locales have different performance patterns? | Multilingual sites may need locale-specific entries or alternates |
| Which pages have high impressions but weak engagement? | Those pages may need clearer summaries, examples, or internal links |
| Which technical issues affect listed URLs? | Do not tell agents to read pages that are blocked, redirected, or canonicalized away |
| Which actions are already assigned? | The file should reflect shipped work, not aspirational pages |
Searvora AI SEO Consultant can then help turn the evidence into decisions: add a page, remove a stale URL, split a huge file into product-specific maps, update schema, or fix crawl blockers before changing the text file.
Use The File As A Maintenance Contract
The most useful llms.txt file is not the longest one. It is the one that makes the site's source of truth obvious.
Run this sequence every month or after major site changes:
- Export the current llms.txt URLs.
- Crawl those URLs and check status, canonical, indexability, title, H1, and internal links.
- Compare the list against the sitemap and core navigation.
- Remove stale or low-context URLs.
- Add new canonical pages that explain products, docs, policies, and evergreen research.
- Check whether key pages have concise summaries, useful headings, and source-quality evidence.
- Review AI-search and organic visibility movement for the listed page groups.
- Record what changed so the next update does not become guesswork.
That is the durable answer to "what is llms.txt?" It is a small file with a large governance question behind it. If your site has important public knowledge, llms.txt can help you declare what matters. If the rest of the site is messy, start there first.