
URL Inspection API automation is useful when a team needs more than one-off Search Console checks. The API can return URL-level information from Search Console, but the value comes from choosing the right URLs, respecting limits, comparing the response with crawl evidence, and turning the result into fixes.
Do not start by asking the API about every URL you can find. Start with a page group, a risk question, and a validation plan. A clean workflow samples the URLs that matter, checks their reported indexing state, compares that state with canonicals, sitemaps, redirects, and internal links, then routes the smallest fix that can be rechecked.
Start With A URL Inspection Job
The public Screaming Frog tutorial on automating the URL Inspection API shows a practical crawler-led path: connect Search Console, enable URL Inspection data, collect results in bulk, and work around daily limits with exports, scheduling, or focused URL sets.
That is the right technical surface, but the SEO decision starts before the API call. Name the job the inspection result should support.
Use this framing before you automate anything:
| Inspection job | URL sample to inspect | Decision it should support |
|---|---|---|
| New content launch | Recently published URLs from the sitemap and internal links | Whether discovery, canonical, and index eligibility are clean |
| Migration validation | Old-to-new redirect targets and priority landing pages | Whether Google sees the final canonical URLs after the move |
| Template regression | Representative URLs from one page type | Whether noindex, canonical, mobile, or rich result issues spread across a template |
| Indexing cleanup | URLs reported as discovered, crawled, duplicate, or not indexed | Whether the issue is access, quality, duplication, or recrawl timing |
| Product or collection review | High-value commercial URLs plus their variants | Whether facets, parameters, or weak links are confusing index selection |
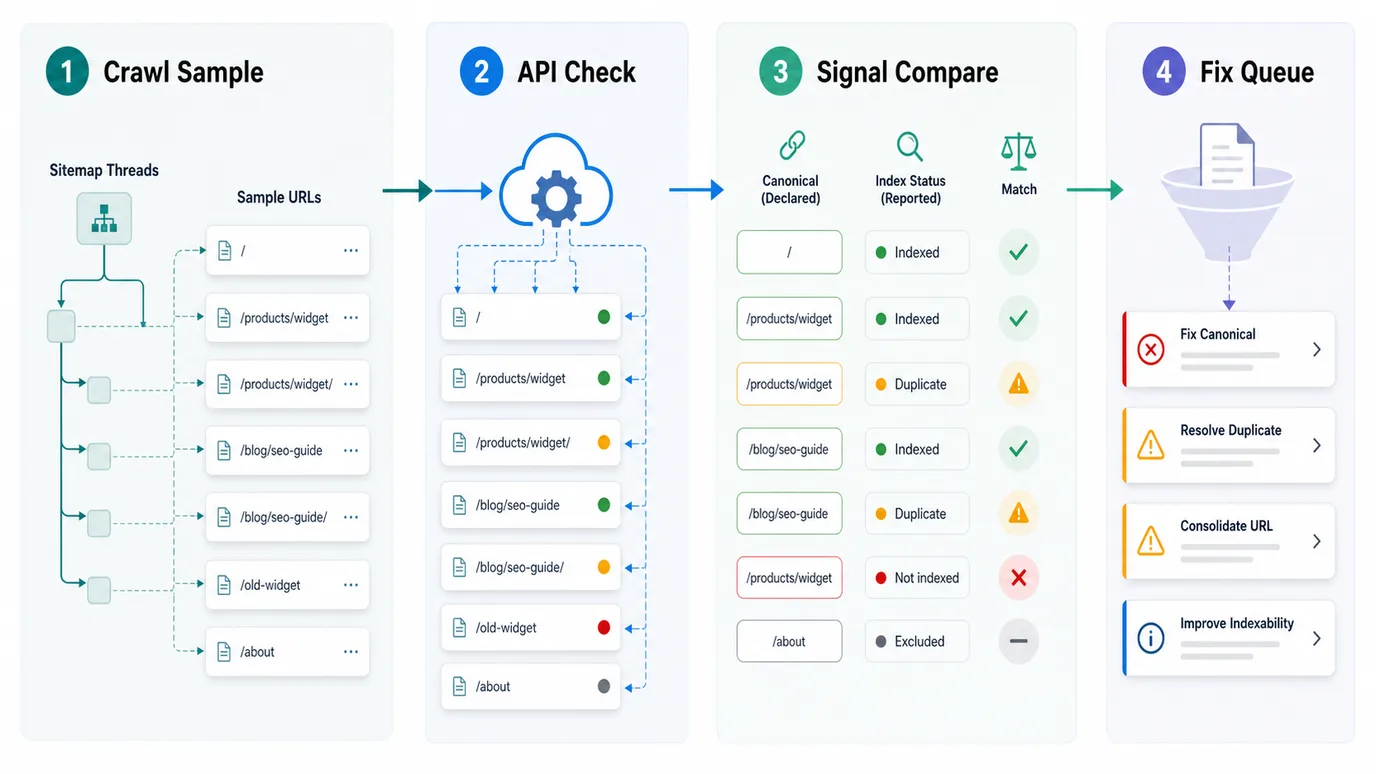
Build The Sample From Crawl And Sitemap Evidence
The fastest way to waste URL Inspection API checks is to feed it a noisy CMS export. Some URLs will redirect. Some will be noindex. Some will be canonicalized away. Some will be internal-only. Those are still useful audit findings, but they should be classified before you ask Search Console for every detail.
Build the inspection sample from crawl evidence first:
- Crawl the section or template group.
- Filter to URLs that should be search-visible.
- Keep final 200 URLs separate from redirects, canonical variants, and blocked pages.
- Join sitemap inclusion, lastmod, internal inlinks, depth, and canonical target.
- Add GSC Performance pages when you need search demand context.
- Split priority URLs from diagnostic samples.
This is where adjacent Searvora workflows become useful. Use the Google indexing workflow when the problem is missing pages, and use the Google Search Console site audit workflow when Search Console is the starting evidence. URL Inspection API automation is narrower: it turns known URL samples into repeatable URL-level checks.
Respect Limits Before You Schedule Checks
Google's official Search Central launch post for the URL Inspection API describes the API as programmatic access to URL-level Search Console data. Screaming Frog's tutorial also calls out the practical daily limit pattern for bulk work. Treat those limits as a planning constraint, not a nuisance to brute force.
Use this quota-safe split:
| URL group | Frequency | Why |
|---|---|---|
| Release-critical pages | Immediately after launch, then after recrawl windows | Confirms whether Google sees the intended version |
| Template samples | Weekly or after deploys | Catches repeated canonical, mobile, or rich result drift |
| Long-tail inventory | Rotating batches | Gives coverage without pretending every URL needs daily inspection |
| Known problem URLs | After a fix ships | Validates the fix instead of refreshing the whole export |
| Low-value variants | Rarely or never | Crawl rules, canonicals, or noindex decisions should handle them first |
The API is not a rank tracker and it is not a full crawler. It reports what Search Console knows for a submitted URL. Your crawl still needs to explain whether the live site is sending the right signals.
Compare API Responses With Crawl Signals
URL Inspection data is most useful when it disagrees with what your site is supposed to send. A page can be in your sitemap but not selected as canonical. It can return a clean 200 but be reported as not indexed. It can be indexed but have enhancement issues. It can be eligible in the crawl but unknown to Google because internal links are weak.
Use a comparison table, not a raw export:
| API or GSC signal | Crawl signal to compare | Likely fix path |
|---|---|---|
| URL is not on Google | Internal links, sitemap inclusion, robots, noindex, canonical | Decide whether the URL deserves indexing, then fix discovery or eligibility |
| User-declared canonical not selected | Canonical tag, duplicate cluster, internal anchors, sitemap URL | Consolidate signals around the preferred URL |
| Page indexed with issues | Mobile, structured data, rendered HTML, template fields | Fix the template and recheck a sample |
| Last crawl is stale | Sitemap freshness, internal links, status code stability | Improve discovery and wait for recrawl before rewriting |
| Rich result invalid | JSON-LD, visible content, required properties | Repair schema only when the page type supports it |
This comparison keeps the team from making the wrong fix. A content rewrite will not solve a canonical conflict. A manual indexing request will not fix a noindex rule. A sitemap resubmit will not repair weak internal links.
Turn Inspection Results Into A Fix Queue
The output should not be "URL Inspection API export complete." It should be a queue that an SEO, engineer, content owner, or release manager can close.
Each item needs five fields:
- URL group, not just one URL.
- Inspection result and timestamp.
- Crawl evidence that explains the likely cause.
- Owner and smallest shippable fix.
- Validation method and next recheck date.
For example, "Google selected a different canonical" is not a full ticket. A better ticket says: "Collection filter URLs under /collections/ self-canonical in rendered HTML, but internal links and sitemap point to parameter variants. Engineering should normalize internal links and sitemap output, then SEO should re-crawl and inspect ten priority URLs after deployment."
The technical SEO site audit workflow is the broader version of this handoff. URL Inspection API automation should plug into that same operating model: evidence, owner, fix, validation.
A Practical Automation Sequence
Use this sequence when the team wants repeatable checks without turning the API into another noisy dashboard:
- Define the site section, release, template, or indexing problem.
- Crawl the affected URL set and group by page type.
- Remove URLs that are intentionally blocked, noindex, redirected, or canonicalized away.
- Pick priority URLs and a rotating diagnostic sample.
- Run URL Inspection API checks for that sample.
- Compare API results with crawl, sitemap, canonical, and internal-link evidence.
- Assign fixes by pattern, not by isolated URL.
- Re-crawl after the fix ships.
- Reinspect only the URLs needed to prove the pattern changed.
- Record the decision so the same template does not regress.
URL Inspection API automation is strongest when it narrows the work. Use it to confirm what Google reports for important URLs, then let crawl evidence explain why. The goal is not a bigger export. The goal is a smaller, better fix queue that proves indexing work changed.