
Googlebot is the crawler Google Search uses to discover and fetch pages. For SEO teams, the practical job is not memorizing user-agent strings. The practical job is proving that important URLs can be discovered, crawled, rendered, understood, and rechecked after fixes ship.
Treat Googlebot work as a validation workflow. Start with the pages that matter, check whether Googlebot can reach them, inspect the rendered output, confirm indexing signals agree, and then turn the findings into a fix queue.
Start With The Pages Googlebot Must Reach
Do not begin by crawling everything. Begin with a controlled URL set that reflects the pages search visibility depends on.
Use this first-pass scope:
| URL group | Why it matters | First Googlebot check |
|---|---|---|
| Product, collection, or pricing pages | These pages often carry commercial search demand | Status, robots access, rendered content, canonical, internal links |
| Blog posts and hubs | They teach search systems what the site is about | Discoverability, title, H1, body sections, author/date, structured data |
| Localized pages | Locale mistakes can split signals or send users to the wrong market | Canonical, hreflang, sitemap, language links, rendered text |
| Recently changed templates | One release can change hundreds of URLs | Baseline crawl, rendered HTML diff, owner, release date |
| Pages losing impressions | Visibility loss needs evidence before rewriting | Crawl eligibility, indexability, SERP appearance, content drift |
Google's Googlebot documentation explains the crawler role at a high level. Your workflow should translate that into a repeatable question: can the crawler reach the same page users and SEO teams expect search systems to evaluate?
Check Access Before You Rewrite Content
If a page cannot be crawled or rendered correctly, content edits may not matter. Start with access and index eligibility, then decide whether the page needs editorial work.
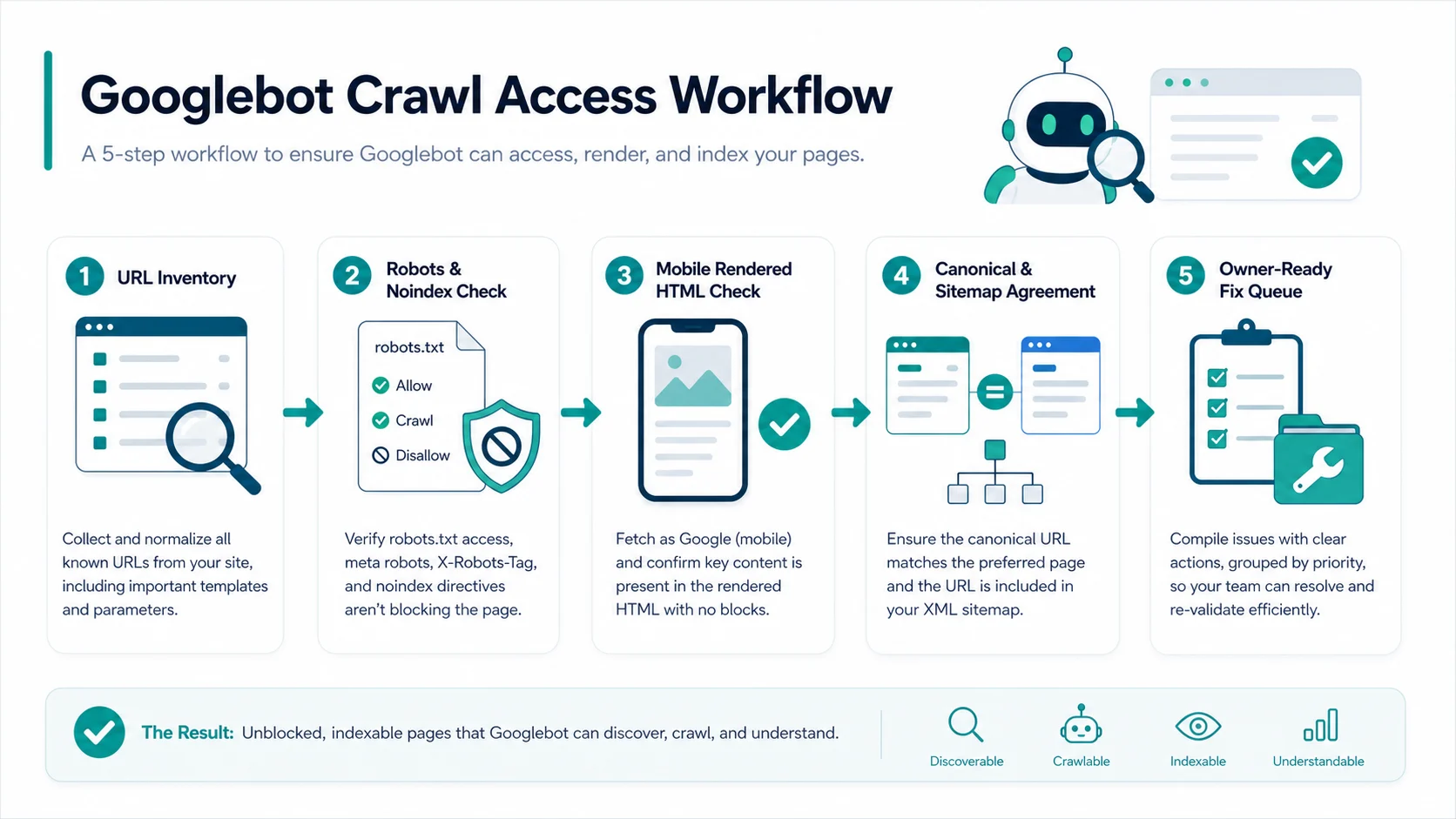
Run this sequence:
| Step | What to check | What blocks the page |
|---|---|---|
| URL inventory | The canonical URL, current status code, redirects, and template group | Important URL missing from crawl scope or returning errors |
| Robots and noindex | Robots.txt access, robots meta tag, and X-Robots-Tag response headers | Disallow, accidental noindex, or user-agent-specific rules |
| Mobile rendered HTML | Primary content, links, metadata, structured data, and resources after rendering | Critical content appears only in a broken client-side state |
| Canonical and sitemap agreement | Canonical URL, internal links, sitemap URL, and hreflang alternates | Signals point to different versions of the same page |
| Fix queue | Issue group, affected URL count, owner, and validation rule | Findings stay as an export instead of assigned work |
The robots layer deserves careful handling. Google's robots meta tag and X-Robots-Tag documentation shows that directives can appear in HTML or HTTP headers. That means a crawl should inspect both the rendered page and response headers before a team assumes Googlebot is allowed to index the URL.
Render The Page Googlebot Actually Evaluates
Modern pages often look fine in a browser and still send weak signals to crawlers. Navigation may depend on JavaScript, content may load late, or important links may exist only as click handlers without crawlable href values.
Use rendered checks for these fields:
- Title, meta description, canonical, and robots directives.
- H1, visible body copy, and the sections that satisfy the query.
- Internal links that help Googlebot discover related pages.
- Structured data that matches visible page facts.
- Images, alt text, and media context when they support the page job.
- HTTP status and redirect behavior after JavaScript and edge logic run.
Google's JavaScript SEO guidance is the official baseline for this part of the audit. The operating rule is simple: validate the rendered output, not only the source template or CMS preview.
This is where Googlebot checks connect to mobile-first indexing. If the mobile rendered version drops links, metadata, schema, or core content, the issue is a search signal problem, not a design preference.
Align Discovery, Canonical, And Sitemap Signals
Googlebot can discover URLs through links, sitemaps, redirects, and other references. A clean site makes those signals agree. A messy site asks crawlers to choose between variants.
Use this signal table before submitting or resubmitting anything:
| Signal | Healthy pattern | Warning pattern |
|---|---|---|
| Internal links | Important pages have crawlable links from relevant sections | The page is orphaned or linked only through filtered states |
| Sitemap | Lists canonical, indexable URLs that deserve discovery | Lists redirects, noindex URLs, parameter variants, or stale pages |
| Canonical | Points to the preferred final URL | Points to another locale, old URL, duplicate, or non-indexable page |
| Redirects | Old URLs resolve cleanly to the intended owner URL | Chains, loops, mixed protocols, or soft 404s dilute the signal |
| Hreflang | Locale alternates reference canonical, live URLs | Alternates point to redirected, noindex, or non-canonical URLs |
Google's sitemap guidance is useful here because a sitemap is not a dump of every URL the CMS can create. It should reinforce the URLs you actually want search systems to discover and revisit.
For the broader cleanup pattern, pair this with the Google indexing workflow and the XML sitemap generator workflow. Googlebot access is the crawler layer; indexing is the eligibility and selection layer.
Separate Real Googlebot From Log Noise
Server logs can reveal whether Googlebot requests important pages, but user-agent strings alone are not proof. If the log sample matters for a security, crawl-budget, or incident decision, verify the crawler identity instead of trusting the label.
Use logs for these jobs:
| Log question | Why it matters | Validation path |
|---|---|---|
| Did Googlebot request the fixed template? | Confirms the page group has been revisited | Compare crawl logs before and after release |
| Are errors clustered by directory? | Finds server, CDN, or rendering failures | Group 4xx, 5xx, timeout, and blocked-resource events |
| Are important URLs ignored? | Suggests discovery or internal-link weakness | Check sitemap inclusion, inlinks, canonical state, and freshness |
| Is the user agent real? | Prevents fake crawlers from distorting decisions | Verify with Google's crawler verification method |
Google publishes verification guidance for Google crawler requests. Keep that as the source of truth when log evidence becomes part of the decision.
Validate Fixes After Launch
A Googlebot fix is not done when a ticket closes. It is done when a recrawl proves the live page now sends the intended signal.
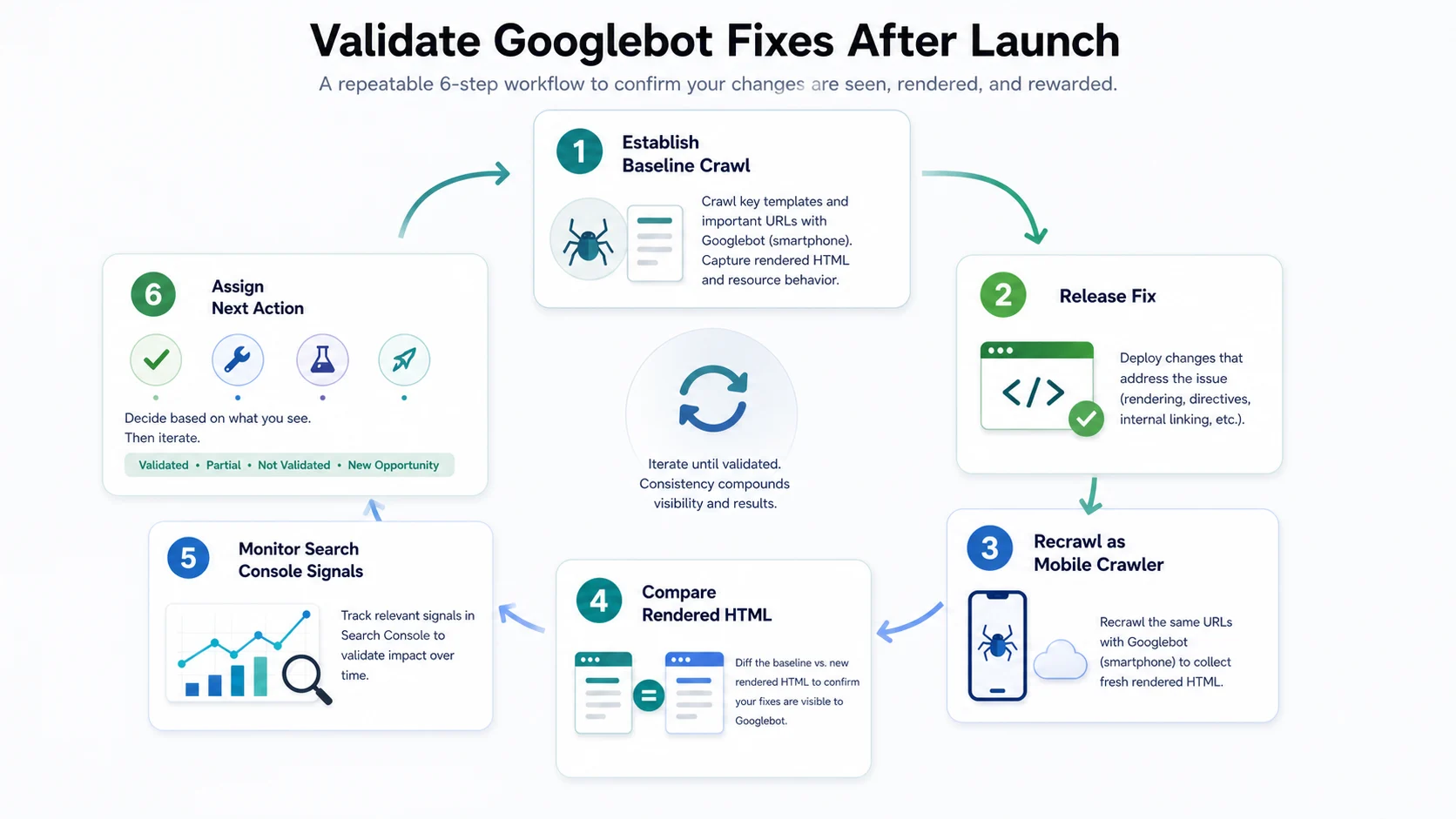
Run this loop:
- Save the baseline crawl, rendered HTML sample, and affected URL group.
- Ship the smallest fix batch that can be checked clearly.
- Re-crawl the same URLs with a mobile crawler context.
- Compare rendered title, body, links, robots, canonical, structured data, and status.
- Monitor Search Console and server logs after Google revisits the section.
- Assign the next action: validated, partially fixed, not fixed, or new opportunity.
For technical SEO teams, the hard part is not finding one warning. It is proving whether the warning changed, whether the right URLs changed, and whether the same template will stay fixed in the next release.
Where Searvora Fits
Searvora SEO Spider Crawler fits the evidence layer of Googlebot work. The product page positions the crawler around JavaScript rendering, robots parsing, canonical and hreflang validation, sitemap discovery, metadata checks, issue clustering, exports, and recurring crawls.
Use the technical SEO crawler when the team needs to move from "Googlebot might not see this" to a reviewable fix queue.
| Workflow step | Searvora role | Output |
|---|---|---|
| Crawl the priority URL set | Gather status, links, canonicals, robots, sitemap, and rendered content | Baseline crawl evidence |
| Group issues by template | Separate isolated misses from structural risk | Owner-ready issue groups |
| Validate mobile output | Check rendered content, metadata, links, and structured data | Proof that Googlebot can evaluate the page |
| Recheck after release | Compare the fixed crawl against the baseline | Validated, partial, or failed fix state |
| Route strategy questions | Send ambiguous page-value decisions to AI SEO Consultant | A prioritized action queue |
Googlebot Audit Checklist
Use this checklist before calling a crawl-access issue solved:
- The URL is meant to appear in search.
- The final response returns a healthy status code.
- Robots.txt allows the intended crawl path.
- Robots meta tags and X-Robots-Tag headers do not block indexable pages.
- The mobile rendered HTML contains the primary content, metadata, and internal links.
- Canonical, sitemap, internal links, and hreflang signals agree.
- Important JavaScript resources are not blocking the rendered page.
- Crawl errors are grouped by template, directory, and owner.
- Server logs are used carefully and real Googlebot requests are verified when the decision depends on them.
- A recrawl after release proves the intended signal changed.
Googlebot is not a mystery crawler to appease. It is a validation surface. When crawl access, rendered content, canonical signals, sitemap discovery, and release evidence line up, technical SEO work becomes easier to trust and easier to assign.