
A pagination SEO audit checks whether page 2, page 3, and deeper list pages can be discovered, understood, consolidated, and validated without wasting crawl attention. The goal is not to add one historical tag and move on. The useful job is to prove how paginated URLs behave in crawl paths, canonicals, internal links, sitemaps, indexability rules, and live search evidence.
The opportunity surfaced from an Ahrefs article on rel=prev/next and pagination plus a Screaming Frog tutorial for auditing pagination attributes. Searvora's angle is the operating workflow around the issue: crawl the whole paginated set, decide what each URL should do, then validate the fix instead of trusting markup alone.
Start With The Pagination Job
Pagination is usually a discovery problem before it is a ranking problem. Category pages, blog archives, product collections, forum threads, and search result lists often expose useful URLs through page sequences. If crawlers cannot follow those sequences, important items sit too deep. If every variant is indexable without control, duplicate or thin list pages can compete with the page that should be the canonical entry point.
Use this first-pass classification before changing tags:
| Paginated set | Main SEO risk | First audit question |
|---|---|---|
| Product category pages | Valuable products are buried or parameter variants multiply | Can crawlers reach deeper products through crawlable links? |
| Blog archives | Old articles lose internal paths or archive pages compete with hubs | Which archive pages should remain discoverable and indexable? |
| Faceted collections | Sort, filter, and page parameters create duplicate inventory | Which combinations deserve crawl access, canonicalization, or noindex? |
| Infinite scroll or load more | Content depends on user action | Is there a crawlable URL path for each meaningful state? |
| Long guides split across pages | Signals disperse across component URLs | Should this be one view-all page, a sequence, or consolidated content? |
Google's pagination best practices are a practical baseline: links between paginated pages should use crawlable anchors, each page should have a unique URL, and the first page should not automatically be used as the canonical for every page in the sequence.
Build A Crawl Map Before Changing Rules
Do not start by asking whether rel="next" and rel="prev" exist. Start by crawling the set and mapping how the pages connect.
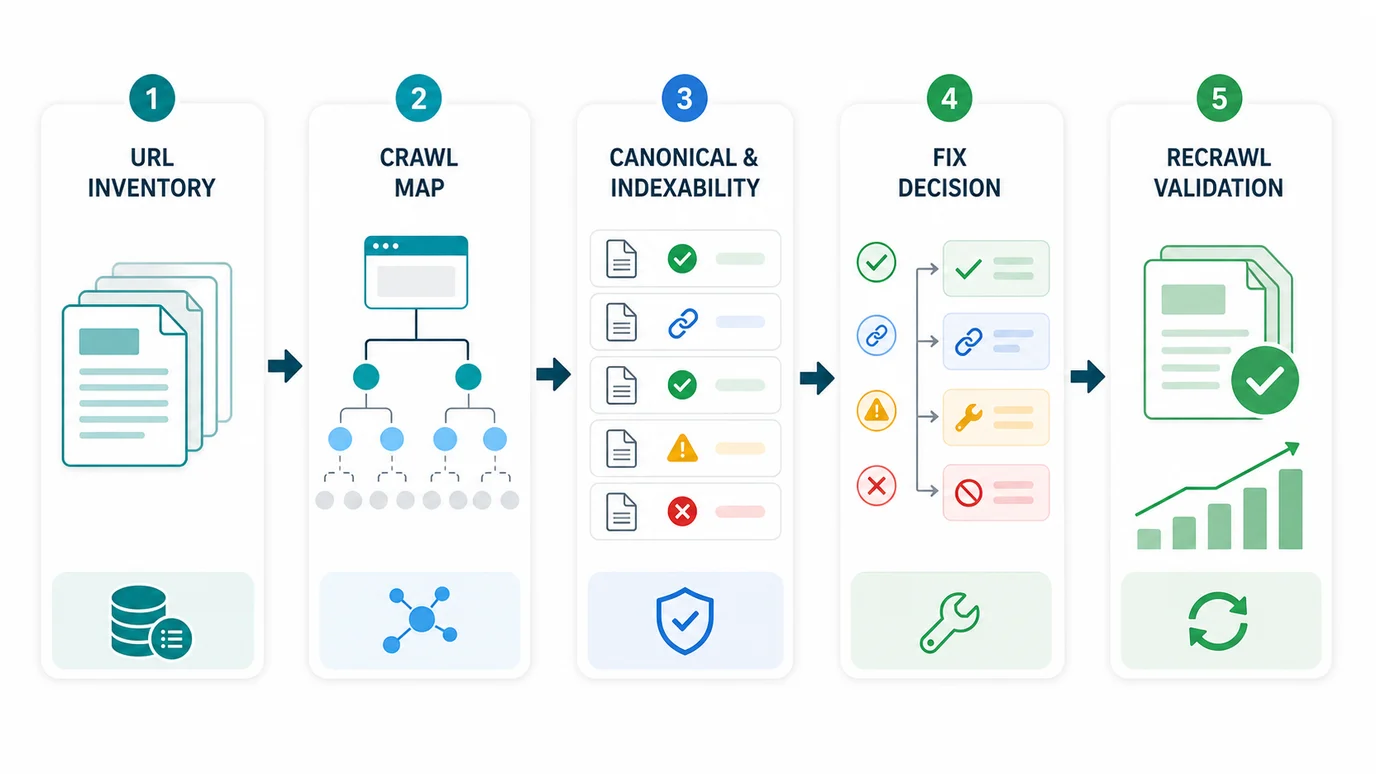
Collect these fields for the full sequence:
| Crawl field | Why it matters |
|---|---|
| Final URL and page number pattern | Shows whether the sequence uses clean paths, query parameters, or fragments |
| Status code and redirect chain | Finds broken or redirected pages inside the sequence |
| Canonical URL | Reveals whether deeper pages self-canonicalize, point to page 1, or conflict by template |
| Indexability and robots rules | Separates pages meant for discovery from pages meant to rank |
| Next and previous links in the body | Proves crawlers can move through the sequence with real anchors |
| Inlinks and crawl depth | Shows whether important paginated pages are too far from the entry point |
| Sitemap inclusion | Confirms whether the site is deliberately submitting component URLs |
| Product or article links found on each page | Shows whether deeper content is actually reachable |
For JavaScript interfaces, compare the rendered DOM with the raw HTML. Google's pagination guidance notes that crawlers generally discover URLs through href attributes and do not click buttons to trigger page updates. If a load-more experience never exposes crawlable URLs, the visual experience may be fine while the search discovery path is weak. Pair this check with the JavaScript SEO workflow when rendered pagination differs from source HTML.
Decide What Each Paginated URL Should Do
The most common pagination mistake is applying one rule to every page. Some paginated URLs should stay indexable. Some should exist only to help discovery. Some should be consolidated. Some should be removed from the crawl path because they are filtered, sorted, empty, or low value.
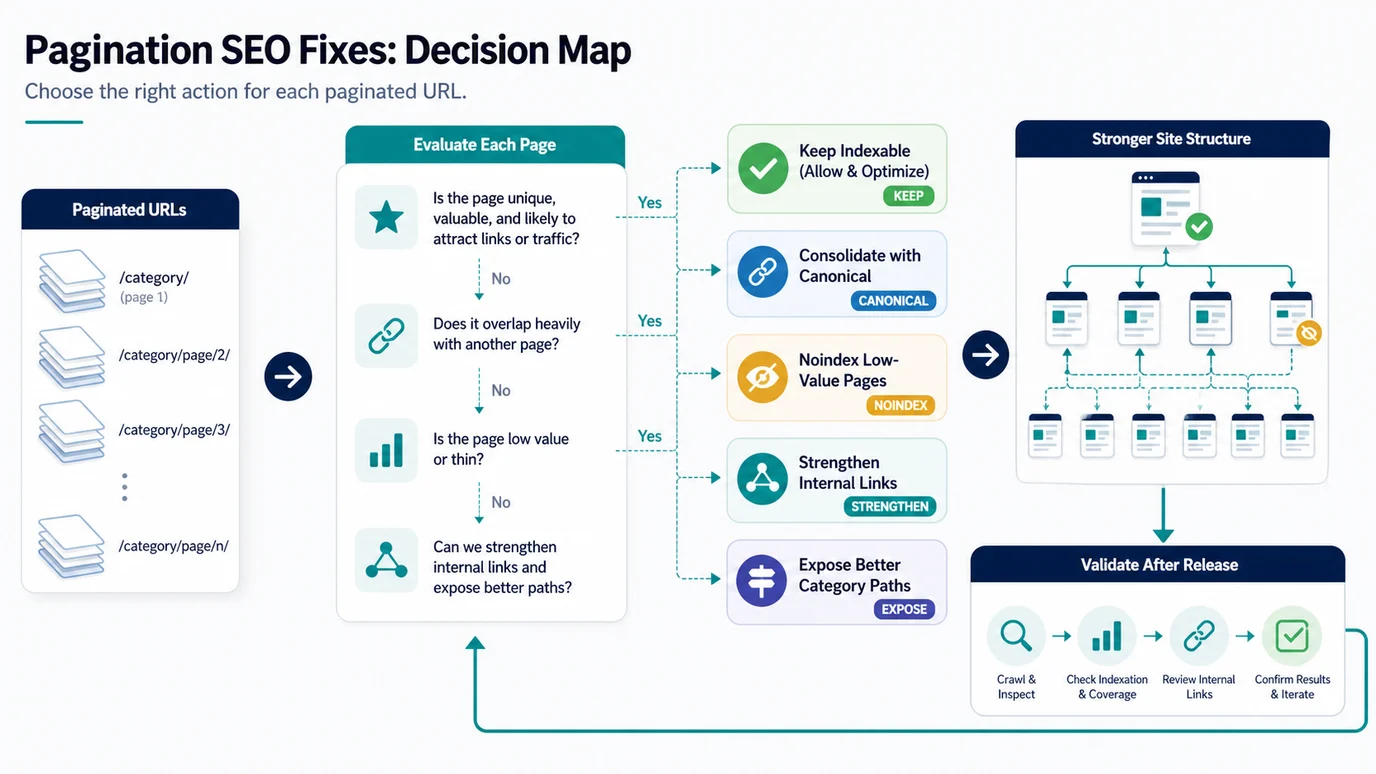
Use this decision table:
| If the paginated URL | Default action | Validation check |
|---|---|---|
| Contains unique useful items and receives meaningful discovery value | Keep crawlable and usually self-canonical | Re-crawl and confirm links, canonical, status, and indexability agree |
| Is a duplicate sort order of the same list | Noindex or control crawl access when appropriate | Confirm the variant is excluded without blocking important item URLs |
| Canonicalizes every page back to page 1 | Review carefully before keeping that pattern | Confirm deeper item links are still discoverable and not orphaned |
Uses fragments such as #page=2 for pagination | Replace with crawlable URLs when the content matters | Confirm crawlers can request each meaningful state |
| Creates many thin parameter combinations | Consolidate, noindex, or block the noisy patterns | Confirm canonical and sitemap signals do not conflict |
| Has no internal links beyond page 1 | Strengthen sequential and hub links | Re-crawl to verify discovery depth improves |
Google's supported meta tags and attributes documentation also states that Google no longer uses next and prev link elements for indexing. That does not mean pagination can be ignored. It means the crawlable links, unique URLs, canonical choices, and indexability rules need to carry the workflow.
Fix The Signals In The Right Order
Pagination fixes become risky when teams change canonical tags, robots rules, and internal links in the same release without a baseline. Use a safer sequence.
- Crawl the current paginated set and save the issue export.
- Identify the entry URL, page sequence pattern, and all page-number variants.
- Check whether each page returns a clean status code and final URL.
- Confirm each meaningful page is reachable through
<a href>links. - Decide which pages should be indexable, self-canonical, canonicalized, noindexed, or retired.
- Remove filtered and sorted variants from sitemaps unless they are deliberate search pages.
- Strengthen internal links from the parent category, hub, or archive when deeper pages matter.
- Update templates in the smallest batch that can be verified.
- Re-crawl the same sequence and compare before and after.
- Monitor page-level search data after enough recrawl time.
For ecommerce and large content libraries, this is closely related to faceted navigation SEO. The question is not whether every variant should be blocked. The question is which URL states deserve discovery, which deserve consolidation, and which should never become search inventory.
Watch For These Pagination Failure Patterns
Pagination issues often hide because page 1 looks healthy. The deeper pages reveal the real template behavior.
| Failure pattern | Why it hurts | Better fix |
|---|---|---|
| Page 2 and beyond canonicalize to page 1 by default | Deeper page signals and item discovery may be weakened | Decide per sequence; do not apply page-1 canonicals blindly |
| Pagination uses buttons without crawlable URLs | Crawlers may not reach deeper items | Expose URLs and anchor links for meaningful states |
| Sort and filter URLs are indexable by default | Search inventory fills with duplicate list variants | Noindex, canonicalize, or block noisy patterns intentionally |
| Old page numbers remain in sitemaps | Crawlers revisit stale or empty lists | Submit only canonical, useful URLs |
| Internal links point to redirected pagination URLs | Crawl paths leak through unnecessary hops | Update links to final canonical URLs |
| Page titles and H1s hide the list context | Search systems see weak or repeated page promises | Keep metadata useful, but do not invent fake unique titles for every page |
If the audit exposes orphaned items, use the orphan pages workflow before adding random links. If the risk is mostly URL parameters and canonical drift, the URL structure SEO workflow is the better companion.
Where Searvora Fits
Searvora SEO Spider Crawler fits when pagination needs to become a repeatable QA workflow instead of a one-off template argument. The local product page positions the crawler around crawl and discovery, indexability and architecture, on-page QA, issue clustering, and implementation-ready handoff. That is the right operating layer for pagination because the problem spans links, canonicals, sitemaps, robots rules, and validation.
| Searvora workflow step | What the team gets |
|---|---|
| Crawl the sequence | A URL inventory for every paginated state and linked item |
| Group by template | Category, archive, search, and faceted paths become easier to compare |
| Inspect indexability | Canonical, robots, sitemap, and status signals can be checked together |
| Prioritize fixes | Teams can separate discovery blockers from low-value cleanup |
| Re-crawl after release | The same sequence proves whether the live fix actually landed |
Pagination SEO Audit Checklist
Use this checklist before shipping template changes, ecommerce filters, archive redesigns, or load-more interfaces:
- Crawl the complete paginated sequence from page 1 through the deepest useful page.
- Confirm every meaningful page has a unique URL and does not rely on fragments for page state.
- Check that next-page and previous-page navigation uses crawlable anchor links.
- Compare canonical targets across page 1, deeper pages, filtered pages, and sorted pages.
- Decide which pages should be indexable and which should only support discovery.
- Remove duplicate sorted or filtered variants from sitemaps unless they are intentional landing pages.
- Confirm internal links point to final URLs, not redirects or stale parameters.
- Check whether important products, articles, or listings are reachable without excessive crawl depth.
- Validate JavaScript pagination with rendered output and source HTML when needed.
- Re-crawl after release and compare status, canonical, indexability, links, and sitemap coverage.
Pagination SEO is clean when the sequence tells one story. Users can move through the list, crawlers can discover the important URLs, canonical signals match the page job, low-value variants stay controlled, and every fix can be proven with a follow-up crawl.