
Website crawlers are software systems that discover URLs, request pages, follow links, read technical signals, and decide what evidence is available for search, audits, or AI answer systems. For SEO teams, the useful question is not only what a crawler is. It is whether crawler output proves which pages can be found, rendered, indexed, trusted, and fixed.
The Ahrefs article that surfaced this competitor opportunity explains the crawler concept for a broad SEO audience. Searvora's information gain is the operating layer around that concept: separate crawler types, map signals to page jobs, and turn crawl evidence into a validation workflow instead of another export.
Know Which Crawler Job You Are Looking At
Different website crawlers answer different questions. Treating them as one generic bot creates messy priorities.
| Crawler type | Primary job | What SEO teams should capture |
|---|---|---|
| Search crawlers | Discover and evaluate pages for search systems | Crawl access, internal links, canonical signals, rendered content, structured data, and freshness |
| Site audit crawlers | Reproduce a site crawl for diagnostics | Status codes, redirects, indexability, metadata, headings, images, internal links, and sitemap state |
| AI crawlers and answer systems | Find source pages that can support AI answers or citations | Crawlable source pages, clear entities, extractable claims, comparison tables, and source-page authority |
| Monitoring crawlers | Recheck known URL sets over time | Template drift, release regressions, broken links, noindex changes, and sitemap changes |
Google's Search Central explanation of crawling and indexing is the baseline: search systems have to discover and process pages before they can rank them. A site audit crawler is your way to inspect whether your own site gives those systems a clean path.
Turn Discovery Into A Crawl Evidence Map
A crawler does not only collect URLs. It builds a map of what systems can reach and what each URL says about itself.
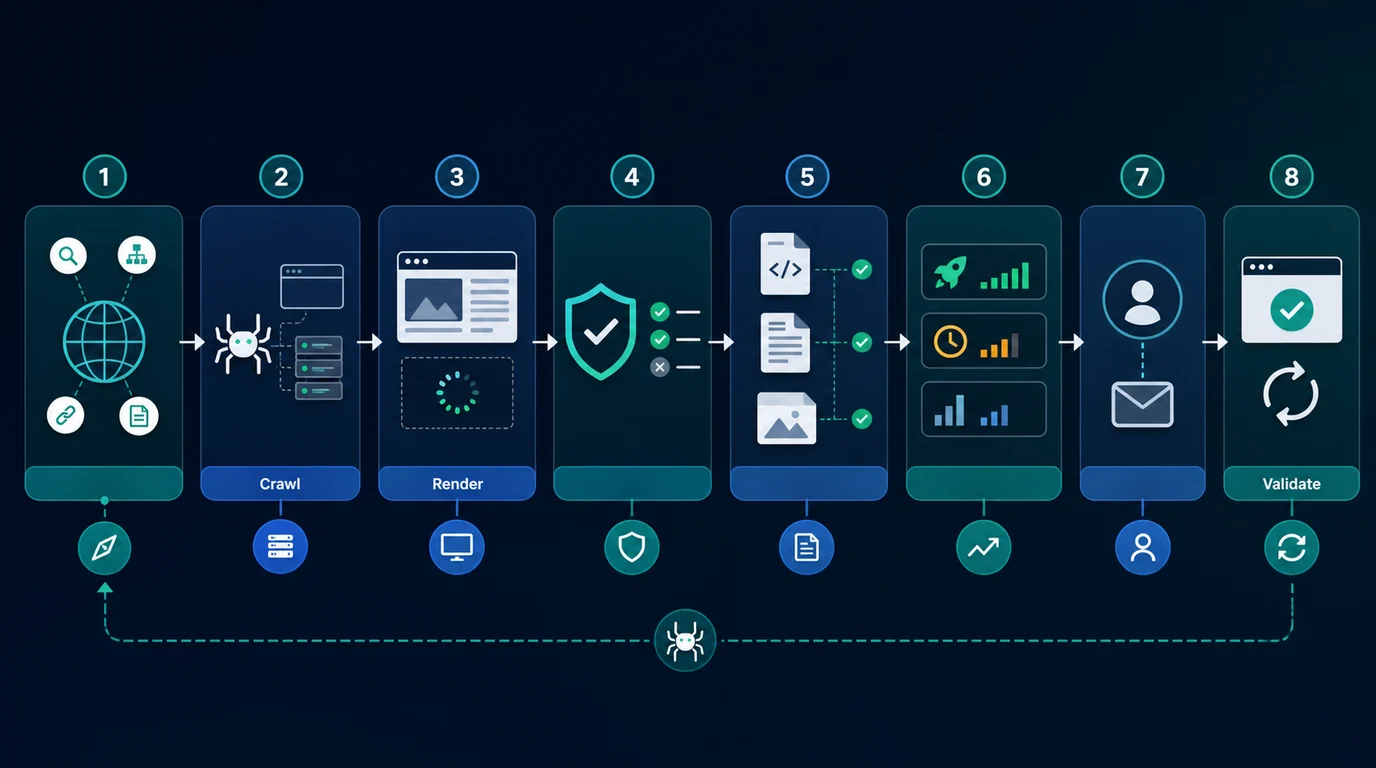
Start by capturing the fields that affect decisions:
| Evidence layer | Crawl signal | Decision it supports |
|---|---|---|
| Discovery | Internal links, crawl depth, sitemaps, orphan status | Can important pages be found naturally? |
| Access | Status code, redirect path, robots rules, noindex state | Can systems request and use the page? |
| Selection | Canonical target, duplicate variants, hreflang alignment | Which URL should represent the content? |
| Rendering | Source HTML, rendered HTML, loaded links, visible copy | Does the final page expose the content and links that matter? |
| Meaning | Title, H1, headings, schema, anchors, examples | Does the page explain a clear search task? |
| Validation | Recrawl result, sitemap agreement, search or AI visibility trend | Did the shipped fix actually change the live output? |
This keeps the article distinct from how to crawl large websites. Large-site crawl planning is about scope and segmentation. Website crawlers as a topic is broader: it explains how crawler evidence becomes the first proof layer for search and AI visibility work.
Separate Crawl Access From Content Quality
Crawler output often gets misread. A page can be easy to crawl but weak as a source. Another page can have strong content but be blocked, canonicalized away, or buried too deep for systems to find.
Use this split before assigning work:
| If the crawler finds | It is probably | Send the first fix to |
|---|---|---|
| 404, 5xx, timeout, redirect loop, or blocked URL | Access problem | Engineering, platform, or CMS owner |
| Wrong canonical, noindex, sitemap mismatch, or hreflang conflict | Selection problem | SEO and engineering together |
| Missing title, duplicate H1, weak internal links, or thin template copy | Meaning problem | SEO, content, or product marketing |
| Rendered HTML hides important copy or links | Rendering problem | Frontend or platform owner |
| Strong page but no supporting links from the cluster | Discovery and authority problem | SEO/content owner |
This is where robots.txt rules matter. Robots controls can reduce crawl waste, but they can also hide the very signals a crawler needs to verify. When the issue is AI-search eligibility, pair crawl access with AI crawlability and GEO checks so the source page is discoverable, canonical, and useful enough to cite.
Build The Fix Queue From Patterns, Not Warnings
The value of website crawlers is pattern detection. One missing H1 may be a page edit. The same missing H1 across every product template is a release problem.
Group findings like this:
| Pattern | Why it matters | Better next action |
|---|---|---|
| Template-level metadata drift | One component can affect hundreds of pages | Fix the template and recrawl the affected URL set |
| Canonicals disagree with sitemaps | Preferred inventory is sending mixed signals | Align canonical, sitemap, redirects, and internal links |
| Important pages are too deep | Search systems and users get weak discovery paths | Add contextual links from hubs, product pages, or related articles |
| JavaScript changes critical links or copy | Source and rendered page tell different stories | Validate rendered HTML before judging content quality |
| AI source pages lack extractable proof | The page is crawlable but hard to cite | Add visible definitions, tables, examples, and source links |
Searvora's SEO Spider Crawler product page positions the crawler around crawl discovery, JavaScript rendering, robots parsing, indexability, canonicals, hreflang, metadata, image checks, issue grouping, and owner-ready action queues. Use that workflow when the team needs crawler evidence to become assigned work instead of an export that sits in a folder.
Validate After The Page Changes
A crawler is most valuable after the fix ships. That is when the team can prove whether the live page now returns the expected status, canonical, metadata, rendered content, links, and sitemap state.
Use this validation loop:
- Save the baseline crawl sample and the page group it represents.
- Write the expected live output before the fix ships.
- Assign the owner and fix path by pattern, not by isolated URL.
- Release the smallest useful batch.
- Recrawl changed URLs plus template peers.
- Confirm status, redirects, robots, noindex, canonical, hreflang, sitemap inclusion, metadata, and rendered content.
- Check whether related search or AI visibility signals move after systems revisit the page.
- Record what changed so the next crawl starts from evidence instead of memory.
The finish line is not "crawl completed." The finish line is "the crawl proved the fix." When a crawler result cannot lead to an owner, acceptance criteria, and recrawl check, the team is still in discovery mode.
Website Crawler Checklist
Use this checklist before treating crawler output as a finished SEO audit:
- Name the crawler job: search eligibility, technical audit, AI-source readiness, monitoring, or release QA.
- Segment URLs by page type, template, directory, locale, and business value.
- Confirm sitemaps represent preferred canonical inventory.
- Check robots rules before assuming a missing URL is a content problem.
- Compare source HTML and rendered HTML when JavaScript can change links, headings, or body copy.
- Separate access, selection, rendering, meaning, and validation issues.
- Group findings by pattern and owner.
- Prioritize issues by organic impact, template footprint, and fix confidence.
- Link each fix to acceptance criteria.
- Recrawl after release and keep the proof attached to the work item.
Website crawlers are not just bots moving through pages. For SEO operators, they are evidence systems. Use them to see what search and AI systems can reach, what signals they receive, which page should represent the topic, and whether the team's fix changed the live site.