
Discovered - currently not indexed means Google knows a URL exists but has not crawled it yet. In day-to-day SEO work, Discovered currently not indexed pages need crawl evidence before they need another submission click. The useful work is to prove that the page is worth crawling, easy to reach, technically eligible, and connected to the rest of the site.
Start with evidence. Check discovery paths, sitemap inclusion, internal links, robots access, noindex rules, canonicals, page value, and template patterns. Then ship the smallest fix batch you can validate with a recrawl and Search Console.
Start With The Actual Search Console Status
Google's Page indexing report documentation separates discovered URLs from crawled URLs. That distinction matters. A discovered URL is in Google's awareness set, but it has not become a crawled, evaluated, indexable page yet.
Do not treat the label as one universal problem. It can come from a new URL waiting its turn, weak internal links, low sitemap trust, crawl budget pressure, robots confusion, duplicate signals, thin content, or a template that creates too many low-value URLs.
Use this first pass:
| Question | Evidence to collect | Fix direction |
|---|---|---|
| How did Google discover it? | Sitemap, internal link, external link, old redirect, or feed | Strengthen the clean discovery path |
| Is it important enough to crawl now? | Page type, demand, business value, freshness, internal links | Prioritize pages that deserve a crawl slot |
| Can crawlers access it? | Status code, robots.txt, meta robots, rendering resources | Remove access conflicts before content work |
| Does it point somewhere else? | Canonical, redirects, duplicate variants | Align preferred URL signals |
| Is the page useful enough? | Unique query job, visible content, template quality | Improve or merge pages before re-submitting |
Build A Diagnostic Path Before Changing Content
The fastest way to waste time is to rewrite the page before you know whether Google can reach it. A content refresh will not help if the URL is orphaned, blocked, canonicalized away, buried in a noisy sitemap, or part of a template that produces hundreds of near-duplicates.
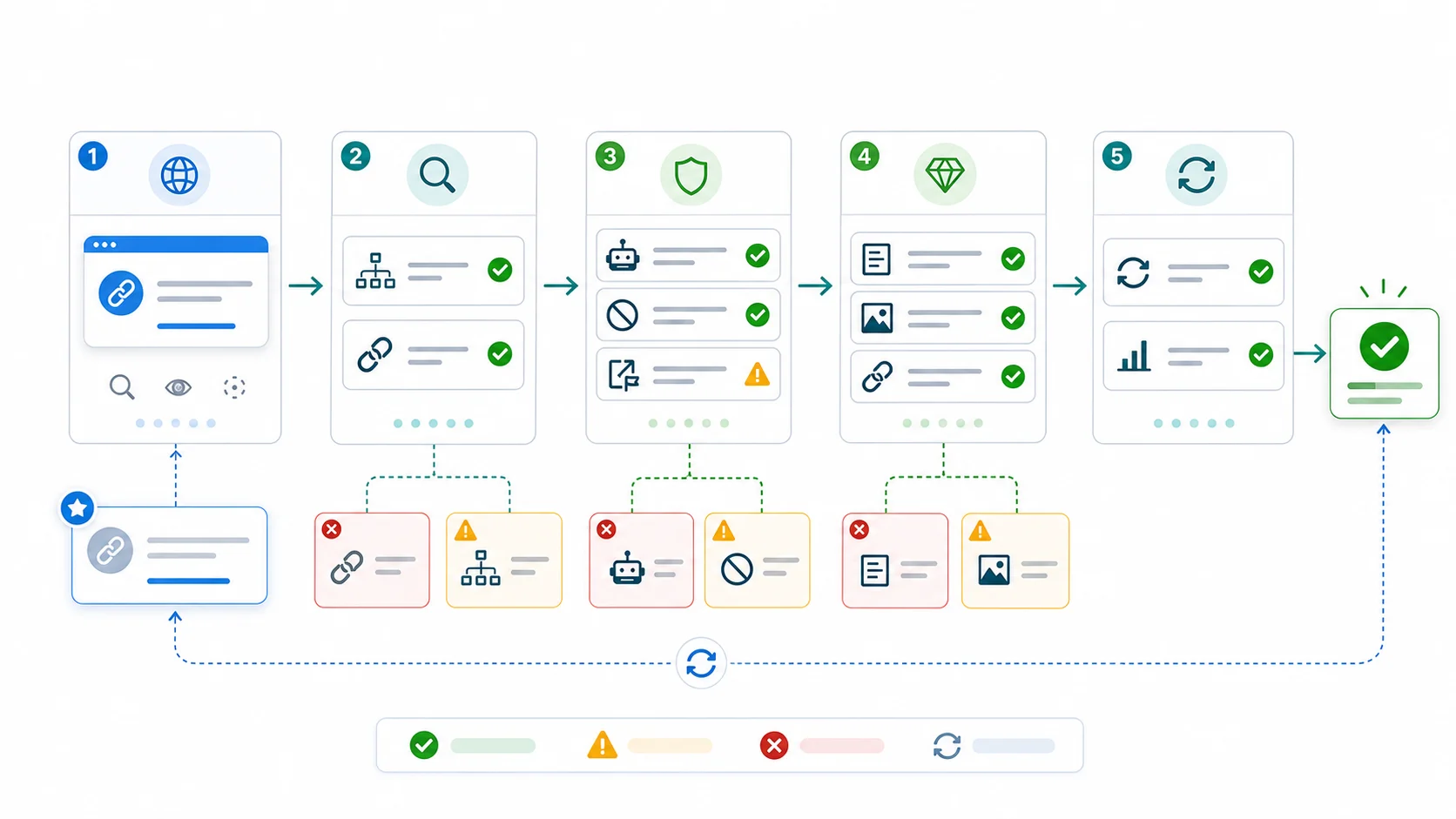
Run the diagnostic in this order:
- Crawl the URL and its template group.
- Confirm the final URL returns a clean 200 status.
- Check whether robots.txt blocks the URL or required rendering assets.
- Confirm the page does not carry an accidental
noindexdirective. - Compare the canonical target with the URL you want indexed.
- Check whether internal links point to the final canonical URL.
- Confirm the URL appears in a clean XML sitemap only if it is indexable.
- Compare the page against nearby duplicates and thin variants.
The parent Google indexing workflow is useful when you need the broader indexing model. This article should stay narrower: why a discovered URL has not earned a crawl yet and what evidence changes that state.
Separate Crawl Delay From Crawl Blockers
Some discovered URLs are simply new. Others are discovered but not crawled because your site is sending weak or conflicting signals. Separate those cases before creating tickets.
| Pattern | What it usually means | Better next step |
|---|---|---|
| New page, strong links, clean sitemap | Google may not have recrawled yet | Wait, monitor, and request indexing only for priority URLs |
| Sitemap-only URL with no internal links | The page is technically listed but not reinforced | Add contextual internal links from relevant indexed pages |
| URL in sitemap but canonical points elsewhere | Signals disagree about the preferred page | Fix sitemap and canonical alignment |
| Orphan URL with thin content | The page has weak value and weak discovery | Improve, merge, or retire before requesting indexing |
| Many similar discovered URLs | Template or parameter pattern may be diluting crawl demand | Group by page type and control low-value variants |
| Robots/noindex conflict | Google may discover a URL but lack useful crawl or index signals | Fix access and eligibility first |
Google's recrawl guidance is direct about expectations: requesting indexing does not guarantee immediate recrawling or indexing. That is why the request should be the last mile of a clean fix, not the first move.
For access rules, pair this check with robots.txt rules. For duplicate URL selection, use the canonical tags workflow. Those controls decide whether the discovered URL is eligible enough to deserve crawler attention.
Fix Discovery Signals First
If a URL is only discoverable through a sitemap, it may still be valid, but it has a weaker site-level vote than a page that is internally linked from relevant hubs, categories, guides, or product pages. Discovery strength matters most when the site has many URLs competing for crawl attention.
Prioritize these fixes:
| Discovery signal | Good pattern | Risk pattern |
|---|---|---|
| Internal links | Relevant indexed pages link to the final canonical URL | Page is orphaned or linked only from low-value archives |
| XML sitemap | Lists canonical, indexable, important URLs | Lists noindex, redirected, duplicated, or stale URLs |
| Navigation and hubs | Page belongs to a clear topic or product path | Page exists as a one-off CMS item with no context |
| Redirect history | Old URLs point cleanly to the intended destination | Chains or outdated redirects create extra crawl work |
| Template footprint | Similar pages have a maintained search job | The template produces many low-value variants |
For sitemap cleanup, the XML sitemap generator workflow is the practical companion. A sitemap should help crawlers discover the right URLs, not dump every CMS route into Google's queue.
Fix Index Eligibility Before Requesting Indexing
Index eligibility is the technical layer. If it fails, Search Console can keep showing discovered URLs while the real blocker sits in page output, robots rules, canonical choices, or template behavior.
Use this eligibility checklist:
- Final URL returns 200 and does not depend on fragile redirects.
- Robots.txt allows crawling for the relevant crawler.
- The page does not include accidental
noindexor blocked rendering resources. - Canonical points to the URL that should appear in search.
- Hreflang, if present, references valid canonical pages.
- Sitemap and internal links agree with the canonical URL.
- Rendered HTML contains the primary content, title, H1, and internal links.
- Structured data, if used, matches visible content.
Google's noindex guidance is especially important here because search systems must be able to crawl a page to see a noindex directive. Blocking the wrong thing can make status interpretation harder, not easier.
If the page is JavaScript-heavy, compare source HTML with rendered HTML. If critical content or links appear only after a fragile client-side step, crawl evidence should show whether search systems can evaluate the real page.
Decide Whether The Page Deserves To Be Indexed
Not every discovered URL should move into the index. If the page has no distinct search job, duplicates another URL, depends on stale generated content, or exists only for internal navigation, the correct fix may be merge, redirect, noindex, or remove from the sitemap.
Use this decision table before writing more copy:
| Page decision | Use when | Action |
|---|---|---|
| Keep and strengthen | The URL serves a distinct search task and has business value | Improve links, sitemap signals, and eligibility |
| Refresh | The URL has demand but weak content or outdated proof | Update the page before requesting indexing |
| Merge | Another URL serves the same keyword, type, and user task | Consolidate content and redirects around the stronger page |
| Noindex | The page is useful to users but not useful in search | Keep crawlable until the directive can be seen |
| Remove from sitemap | The URL should not ask for crawler attention | Submit only canonical, indexable, useful URLs |
This is where technical SEO and content strategy meet. If the page is important but thin, treat it as a content-quality fix. If the page is strong but isolated, treat it as an internal-link fix. If the page is one of many variants, treat it as a template governance problem.
Validate The Fix As A Loop
The finish line is not a status change screenshot. The finish line is a validated live state: the URL is discoverable, crawlable, eligible, useful, and monitored after Google revisits it.
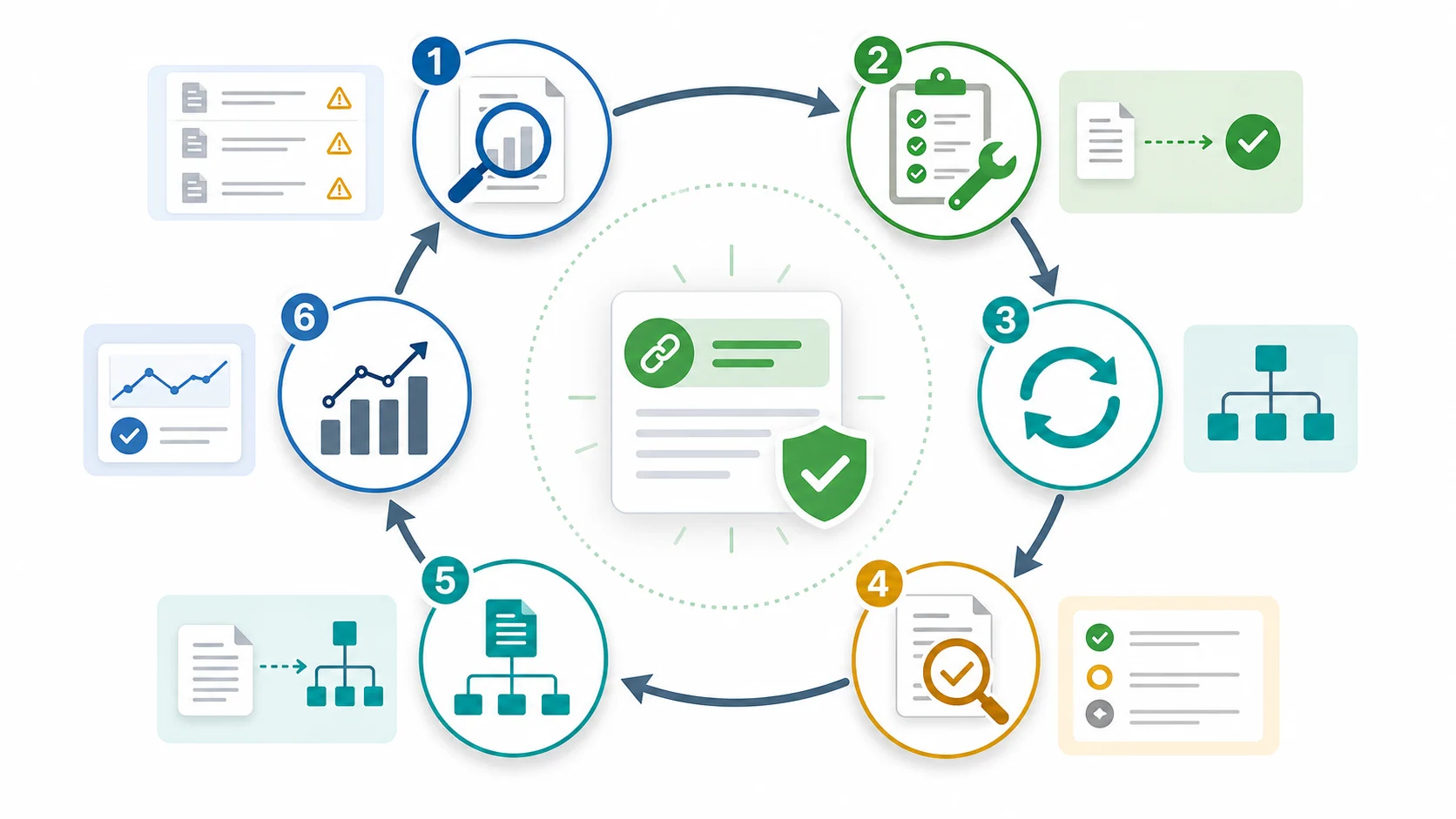
Run this loop:
- Save the starting Search Console status and crawl evidence.
- Group affected URLs by template, directory, page type, or sitemap source.
- Ship the smallest fix batch that can be checked clearly.
- Re-crawl the affected pages and template peers.
- Confirm live status, robots, noindex, canonical, links, sitemap, and rendered content.
- Use URL Inspection for priority URLs after the live evidence is clean.
- Monitor Page indexing, impressions, and crawl behavior after recrawl windows.
- Record the fix rule so the template does not regress.
The URL Inspection tool documentation is useful for checking individual URLs, but one-off inspection should not replace a crawl-backed workflow. If five pages in the same template show the same status, fix the pattern and validate the group.
Where Searvora Fits
Searvora SEO Spider Crawler helps when Discovered - currently not indexed needs to become an evidence queue instead of a set of isolated URL checks. Use it to crawl status codes, redirects, canonicals, robots directives, internal links, sitemap inclusion, rendered content, and template groups before assigning work.
| Workflow step | Searvora role | Output |
|---|---|---|
| Baseline crawl | Collect access, indexability, internal-link, and sitemap signals | Evidence for why the URL may not be crawled |
| Template grouping | Separate isolated pages from structural patterns | Better owner and priority decisions |
| Fix handoff | Route blocked, orphaned, thin, or duplicate pages to the right team | SEO, content, engineering, or CMS action queue |
| Validation crawl | Compare live output after fixes ship | Proof that the crawl signals changed |
Use AI SEO Consultant when the technical evidence creates a strategic choice: improve the page, merge it into a stronger URL, create a hub, noindex it, or remove it from the sitemap. The crawler finds the signals; the decision layer turns those signals into work your team can defend.
Use This Checklist Before You Request Indexing
Run this checklist when a priority URL is stuck as discovered but not indexed:
- Confirm the page should appear in search.
- Crawl the URL and similar template pages.
- Verify the final URL returns 200.
- Check robots.txt, meta robots, and rendered HTML.
- Confirm canonical, sitemap, and internal links agree.
- Add contextual internal links from relevant indexed pages.
- Remove stale, redirected, noindex, and duplicate URLs from sitemaps.
- Improve thin pages before asking Google to crawl them again.
- Re-crawl after fixes ship.
- Use URL Inspection only after the live evidence is clean.
- Monitor the Page indexing report after Google has time to revisit.
- Save the decision and owner so the issue does not return.
Discovered - currently not indexed is not a mystery label. It is a reminder that discovery alone is not enough. The page still needs crawl priority, clean eligibility signals, a distinct search job, and a validation loop that proves the fix changed the live site.